![]()
SKataRT is a Max for Live device which brings together concatenative synthesis techniques from Catart and synthesis techniques by mosaicing.
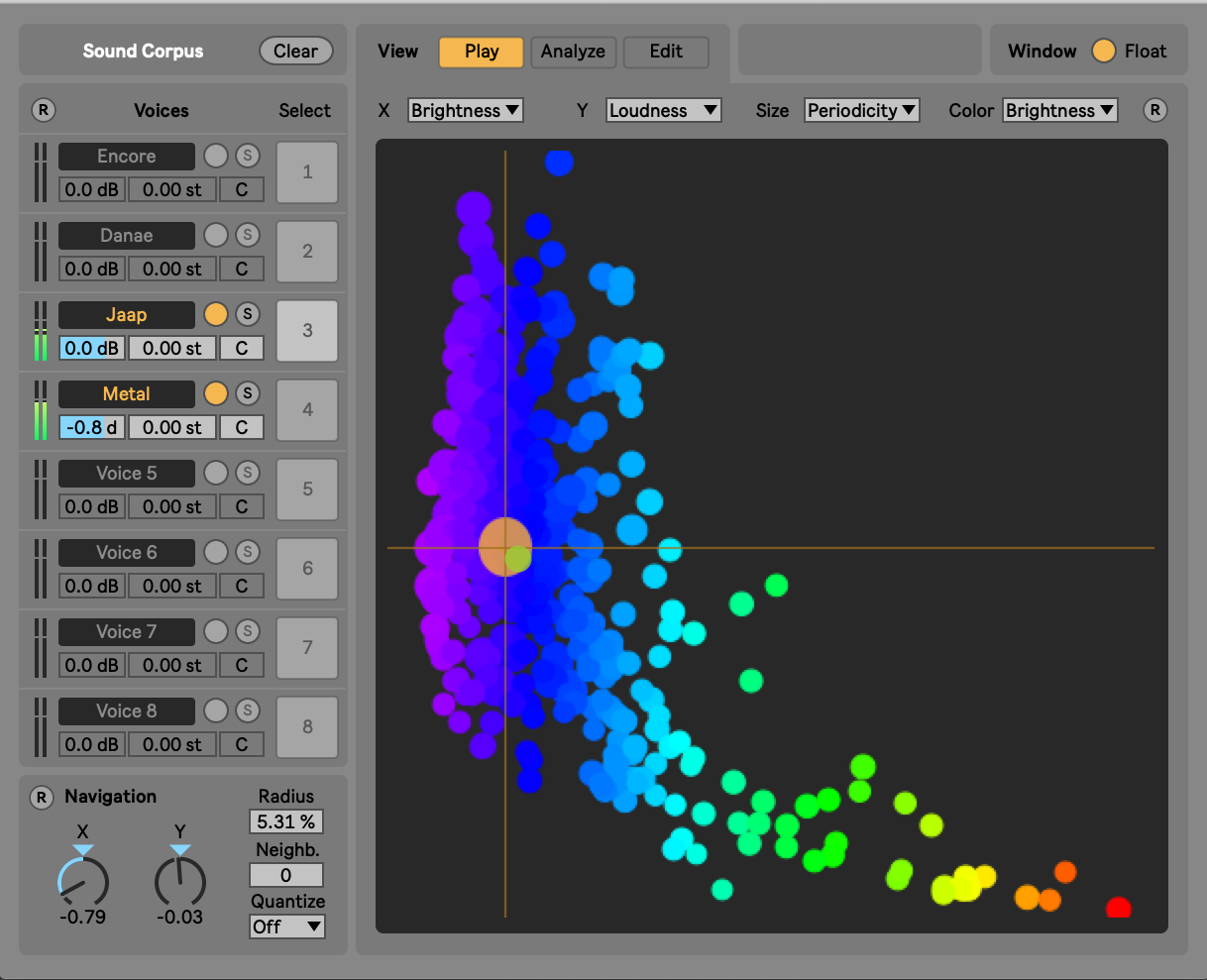
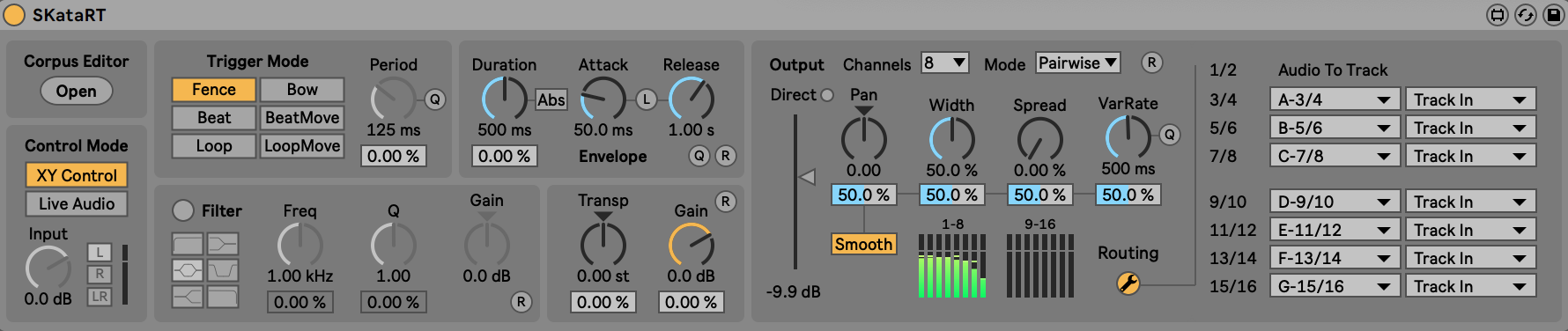
There are two ways of synthesizing sounds: XY and Live Audio modes
The XY mode
The concatenative real-time sound synthesis system SkataRT plays grains (also called units) from a large corpus of segmented and descriptor-analysed sounds according to proximity to a target position in the descriptor space. This can be seen as a content-based extension to granular synthesis providing direct access to specific sound characteristics. The architecture allows, moreover, to mix several sound corpora, which can correspond to different textures (materials) or sound qualities (e.g., concrete vs. abstract).
The Live audio mode

The first idea is to capture a vocal production or an audio sample and modeling it as a parametrizable sound sketch. The vocal or audio signal is described according to its morphological and timbre dimensions. The associated acoustic descriptors are used as input parameters of the corpus-based synthesis system. The process makes it possible to generate a synthetic version of the sketch having some acoustic similarities with the original audio production while allowing to deviate from it and to explore other dimensions.
Authors
SkataRT is derived from CataRT-MuBu by Diemo Schwarz (ISMM team) + contributors, and MIMES by Olivier Houix, Patrick Susini Nicolas Misdariis (PDS team), Frédéric Bevilacqua (ISMM Team).
Max4Live port by Manuel Poletti, Thomas Goepfer (IRCAM / Music Unit), Diemo Schwarz, Riccardo Borghesi (ISMM team).
Consulting and quality control by Jean Lochard (IRCAM). Based on MuBu for Max by Norbert Schnell, Riccardo Borghesi, Diemo Schwarz and the ISMM team.
We acknowledge financial support by the Skat-VG EU project No. 618067 coordinated by Davide Rochesso.
![]()
![]()
![]()
![]()
©IRCAM, 2020. All Rights Reserved. 1, place Igor-Stravinsky 75004 Paris +33 1 44 78 48 43