- Zoom
Linear Predictive Coding
Linear predictive coding (LPC) is a method for signal source modelling in speech signal processing. It is often used by linguists as a formant extraction tool. It has wide application in other areas. LPC analysis is usually most appropriate for modeling vowels which are periodic, except nasalized vowels. LPC is based on the source-filter model of speech signal[1].
Generalities
First, the observation of input and output sequences produces a model, with a number of poles[2], or formants[3] .
A resulting set of coefficients can then describe the behaviour of a system which is not known yet. It is used for predicting a sample. This set of coefficients is an all-pole model, a simplified version of the acoustic model of the speech production system.
The analysis then estimates the values of a discrete-time signal as a linear function of previous samples. The spectral envelope is represented in a compressed form, using the information of the linear predictive model.
Its main advantage comes from the reference to a simplified vocal tract model and the analogy of a source-filter model with the speech production system. It is a useful methods for encoding speech at a low bit rate.
Method
The LPC method is quite close to the FFT. The envelope is calculated from a number of formants or poles specified by the user.
The formants are estimated removing their effects from the speech signal, and estimating the intensity and frequency of the remaining buzz. The removing process is called inverse filtering, and the remaining signal is called the residue.
The speech signal – source – is synthesized from the buzz parameters and the residue. The source is ran through the filter – formants –, resulting in speech.
The process is iterated several time is a second, with "frames". A 30 to 50 frames rate per second yields and intelligible speech.
The LPC performance is limited by the method itself, and the local characteristics of the signal.
The harmonic spectrum sub-samples the spectral envelope, which produces a spectral aliasing. These problems are especially manifested in voiced and high-pitched signals, affecting the first harmonics of the signal, which refer to the perceived speech quality and formant dynamics.
A correct all-pole model for the signal spectrum can hardly be obtained.
The desired spectral information, the spectral envelope is not represented : we get too close to the original spectra. The LPC follows the curve of the spectrum down to the residual noise level in the gap between two harmonics, or partials spaced too far apart. It does not represent the desired spectral information to be modeled since we are interested in fitting the spectral envelope as close as possible and not the original spectra. The spectral envelope should be a smooth function passing through the prominent peaks of the spectrum, yielding a flat sequence, and not the "valleys" formed by the harmonic peaks.
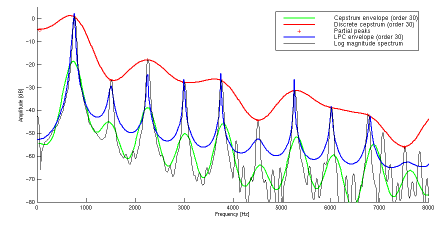
LPC usually requires a very good speech sample to work with, which is not always the case with omnidirectional microphones recordings.
Executing the Analysis
Choose the
Analysis/Sonogram Analysismenu.Pick the
LPCmenu item in theAnalysis Typepop up menu.Enter the parameters of the FFT and specify a number of poles of the LPC order.
The order of an LPC model is the number of poles, or formants in the filter. Usually, two poles are included for each formant. Two to four poles are added to represent the source characteristics. The LPC order is related to the sample rate of the audio file:
10000 Hz - LPC order = 12-14 (males) and 8-10 (females);
22050 Hz - LPC order = 24-26 (males) and 22-24 (females).
By default, the number of pole is equal to 30. The number of poles can be calculated as follows :
N Poles = SR/(F0max*0.25)
Exemple : Number of Poles and Resolution




- Source Filter Model of Speech
Vocal sounds are produced by an excitator, the glottis. The resulting signal has a pitch and an intensity. The resonators are the cavities of the phonation apparatus, which give rise to formants. Hisses and pops are produced by the tongue, lips and throat.
- Pole
The acoustics of the vocal tract are often modelled using a mathematical model of a filter . The frequencies of the poles of this filter model fall close to those of the formants. As a result, some voice researchers now refer to the frequencies of the poles as formants in a mathematical filter model –a property of a model.
- Formant
Formants were originally defined as spectral peaks in a sound spectrum. Resonance and formant are conceptually distinct, but some writers about the voice use the terms interchangeably. Second, the acoustics of the vocal tract are often modelled using a mathematical model of a filter, where the frequencies of the poles of this model fall close to those of the formants. As a result, some voice researchers now refer to the frequencies of the poles as formants.
Hence, it can be : a peak in the spectrum, a resonance of the vocal tract, or a pole in a mathematical filter model.
In acoustics a formant is originally a broad peak in the spectral envelope of the sound. The singers formant and actors formant are broad peaks in the spectral envelope occurring around 3 kHz. In vocal sounds, formants result into vowels.
- Linear Predictive Coding
