AudioSculpt 2.9
Manuel Utilisateur AudioSculpt 2.9.2
|
| “Generalized Cross Synthesis” : synthèse croisée généraliséeLa synthèse croisée généralisée est, sous sa forme la plus flexible (Mode : “Cross”), une combinaison linéaire (un mixage) des spectres des sons originaux et du “spectre produit” (le “spectre produit” résultant de la mutliplication des amplitudes des spectres des deux sons orignaux). Ceci permet de doser la présence des sons originaux et du son résultant du produit des spectres. De plus, afin de compenser la modification de dynamique du produit spectral qui différe selon que les spectres ont des valeurs plus petites que 1.0 ou non, le produit est élevé à une puissance réglable par l'utilisateur. Par exemple, si deux partiels du “spectre produit” ont des amplitudes respectives de 0.2 et 0.5, la dynamique est de 0.5/0.2 = 2.5. Après élévation à la puissance 2 (> 1), la dynamique est accrue pour passer à 6.25. Si on élève à la puissance 0.5 (< 1), la dynamique est atténuée pour atteindre 1.58. Pour le mode “Cross" les spectres d'entrée (amplitude et phase) des deux signaux sont représentés en mode amplitude et fréquence (i.e. via les vitesses d'évolution des phases). Le spectre d'amplitude résultant du traitement est donné par l'expression suivante : ASpec_Out = (AS1 * ASpec_In1) + (AS2 * ASpec_In2) + QS * (ASpec_In1 * ASpec_In2) ^ QE Où :
et où :
Les phases du son de sortie sont alors manipulées via les fréquences (i.e. via les vitesses d'évolution des phases).La fréquence de sortie est calculée comme combinaison linéaire des fréquences d'entrée : FSpec_Out = (FS1 * FSpec_In1) + (FS2 * FSpec_In2) avec :
Il est important de savoir que pour un résultat proche des sons réels, la somme des pondérations FS1 et FS2 doit être proche de 1. Par exemple, une valeur de FS1 proche de 1, avec une valeur de FS2 proche de zéro imposera une structure de partiels proche de celle du son 1. Dans la boîte de dialogue “Generalized Cross Synthesis”, vous avez accès à deux modes : “Cross” ou “Add” chacun sous forme constante (“Constant”) ou variable au cours du temps ("Dynamic”), soit les options :
Le son ouvert (ou en premier plan) est le son 1. Dans le menu “Processing”, faites “Generalized Cross Synthesis”. Le panneau de réglage s'ouvre : 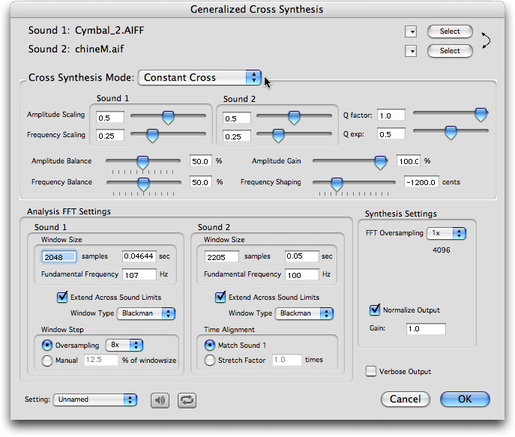 Panneau de réglage “Generalized Cross Synthesis” Choix des sons
Reportez-vous à la section : "Source Filter Synthesis” : synthèse croisée par source/filtre : choix des sons. # Remarque importante : Les sons choisis doivent avoir le même taux d'échantillonnage. Choix des modes et réglages des paramètres
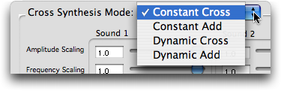 Choix des modes • “Constant Cross” Cela correspond au principe de traitement précédemment exposé. Les paramètres introduits correspondent aux paramètres de l'interface de la façon suivante :
Tous ces paramètres sont réglables par des potentiomètres linéaires. Mais il est plus aisé d'expérimenter (et notamment en temps réel) en utilisant les 4 premiers paramètres de manière indirecte, via 4 autres paramètres réglables par 4 potentiomètres linéaires qui sont :
Vous pouvez remarquer que le déplacement de ces potentiomètres agit sur les valeurs de AS1, AS2, FS1 et FS2. Il est ainsi possible de noter et récupérer des valeurs de ces paramètres pour les utiliser dans les fichiers de paramètres de l'option dynamique. Deux autres potentiomètres linéaires pilotent les valeurs de Q factor et Q exp.  Les paramètres pour “Constant Cross” • “Constant Add” Il s'agit là d'une simple addition des spectres des sons qui donne un résultat proche d'un mixage ; dans ce cas, seuls les paramètres contrôlant l'amplitude de chaque son sont à définir.  Les paramètres pour “Constant Add” • “Dynamic Cross” et “Dynamic Add” - “Dynamic Cross” : synthèse croisée variable dans le temps, - “Dynamic Add” : addition des sons (mixage) variable dans le temps. Pour ces deux dernières options, il faut choisir un fichier au format texte, préparé auparavant :
Les paramètres :
Il faut noter que “Q exp” n'est pas variable dans le temps et que, lors de l'utilisation d'un tel fichier, sa valeur est toujours égale à 1/2 (défaut). Ces valeurs peuvent être définies lors de l'expérimentation en temps réel (voir ci-dessus).  Choix du fichier de paramètres pour “Constant Add” # Remarque importante : Les fichiers doivent bien être enregistrés au format texte-ASCII (avec l'extension “.txt” comme “Mon_Fichier_Param.txt”). L'application “TextEdit”, par exemple, enregistre au format RTF par défaut. Le bouton “Select” ouvre une fenêtre de dialogue standard, permettant de naviguer dans l'arborescence de vos disques durs et d'y choisir un tel fichier. Par ailleurs, à côté du bouton “Select”, un menu déroulant permet de choisir parmi les fichiers récemment utilisés. Le bouton “Check Parameter File” permet de vérifier si le fichier texte choisi est correctement écrit et est cohérent avec le mode demandé (“Cross” ou “Add”).  “Analysis Settings” • Taille et type de fenêtres (“Window Size” et “Window Type”) Reportez-vous à la section : Les paramètres généraux d'analyse. • Le pas d'avancement (“Window Step”) Pour le son 1 (“Sound 1”), reportez-vous à la section : Les paramètres généraux d'analyse. Pour le son 2 (“Sound 2”), le pas d'avancement (“Window Step”) est géré par “Time Alignment”. Vous avez le choix entre :
La durée du fichier de sortie sera donc identique à celle du fichier du son 1.
Le traitement s'applique toujours à partir du début du son 1. Si la durée imposée au son 2 est inférieure à la durée du son 1, le fichier de sortie se verra imposer cette même durée (le traitement ne s'appliquera que sur le début du son 1). Si la durée imposée au son 2 est supérieure à la durée du son 1, le fichier de sortie aura la durée du son 1: ne sera pris en compte pour le traitement que la portion (à partir du début) de son 2 correspondant à la durée du son 1. Pour les autres réglages, reportez-vous à la section : Les paramètres généraux d'analyse. Synthesis Settings
 “Synthesis Settings” • “FFT Oversampling” La FFT est supérieure ou égale à la plus grande des deux tailles de fenêtre des deux sons. “FFT Oversampling” sert aussi pour l'analyse (les deux tailles de FFT sont identiques pour l'analyse et la synthèse). Vous pouvez vous reporter à la section : Les paramètres généraux d'analyse. • Normalisation (“Normalize Output”) et gain Pour le calcul, le son de sortie est normalisé par défaut, car les risques de saturation sont relativement importants dans ce type de traitement. Mais il est possible de désactiver cet automatisme en décochant la case : dans ce cas, seulement, c'est le gain réglable (par le champ “Gain”) qui est pris en compte. # Remarque : Le gain réglable (par le champ “Gain”) est essentiellement utilisé par le mode temps réel afin d'éviter la saturation en sortie (la normalisation n'est pas utilisable en temps réel). En bas du panneau
 • Les boutons dédiés au temps réel : le premier déclenche la pré-écoute en temps réel et le second met cette lecture en boucle. • “Verbose Output” (par défaut non cochée) : Si vous cochez cette option (pour les utilisateurs avertis : flag –v dans SuperVP et Pm2), toutes les informations données par SuperVP ou Pm2, outre la ligne de commande, s'afficheront dans la fenêtre de la console SuperVP, qui, dans ce cas, se dépliera automatiquement. • “Setting” : permet de choisir des paramètres prédéfinis. # Remarque : Il est conseillé d'expérimenter avec un suréchantillonage (“FFT Oversampling”) de 1 et de 2, mais il est inutile d'aller au-delà. Lancement du calcul
Après avoir défini vos paramètres, vous validez par “OK”. La palette de réglage se referme et une fenêtre de dialogue standard s'ouvre, vous demandant sous quel nom et à quel endroit vous désirez enregistrer le résultat (par défaut dans le dossier “Sounds”). Le choix fait, vous validez par “OK”. Cette fenêtre se referme et le calcul se lance. Une fois le calcul terminé, une nouvelle fenêtre AudioSculpt s'ouvre montrant le résultat (cette fenêtre porte le nom du nouveau son). |
© Ircam |